
Simple ASP.NET Core web app using Dapper and SQLite
Here's a simple ASP.NET Core web app using Dapper to access a SQLite database containing authors, articles and tags associated with the articles. You can download the source from GitHub.
I wanted to figure out how to use Dapper to fetch data in a many-to-many relationship. The tags are stored centrally in the tag table. The many-to-many relationship between tags and articles is managed through the articleTag table which links tag records to article records.
This is the entire SQLite database schema :
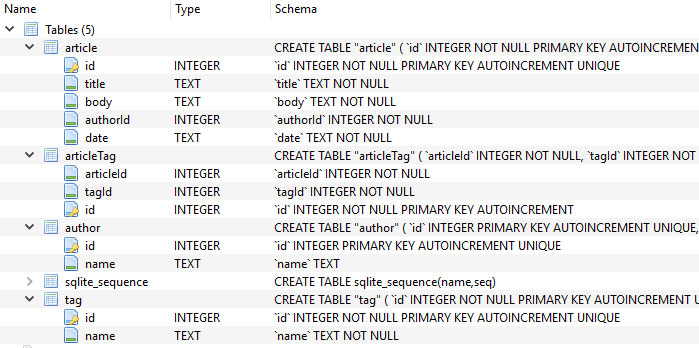
Here is how I fetch articles, their authors and the associated tags :
public List<Article> Fetch(int? tagId = null, int? articleId = null)
{
var articles = new Dictionary<long, Article>();
var sql = @"select * from article
left join author on article.authorid = author.id
left join articleTag on articleTag.articleId = article.id
left join tag on tag.id = articleTag.tagId";
dynamic parameters;
sql += Fetch_ComposeWhereClause(out parameters, tagId, articleId);
// NOTE: I had to create an <ArticleTag> type here because Dapper seems to look at each joined table in turn and tries to
// to map it, regardless of whether I only return the columns I want. I do nothing with the articleTag data
// here as I only need the associated tag data.
var result = _connection.Query<Article, Author, ArticleTag, Tag, Article>(
sql,
(article, author, articleTag, tag) => {
if(!articles.ContainsKey(article.Id))
{
article.Author = author; // Only one author, they'll all be the same one so just reference it the first time.
if(tag != null && article.Tags == null)
{
article.Tags = new List<Tag>();
}
articles[article.Id] = article;
}
else
{
article = articles[article.Id];
}
if(tag != null)
{
article.Tags.Add(tag);
}
return article;
}, (object)parameters);
if(articles.Count > 0)
{
return articles.Values.ToList();
}
return null;
}The main problem this solves is assigning one or more tag records to a single article record when article and tag data are bundled together in multiple result rows (one for each tag). I solve this by transforming the flat results into a dictionary :
var articles = new Dictionary<long, Article>();This solution makes sense when you look at some example results from the above SQL command :
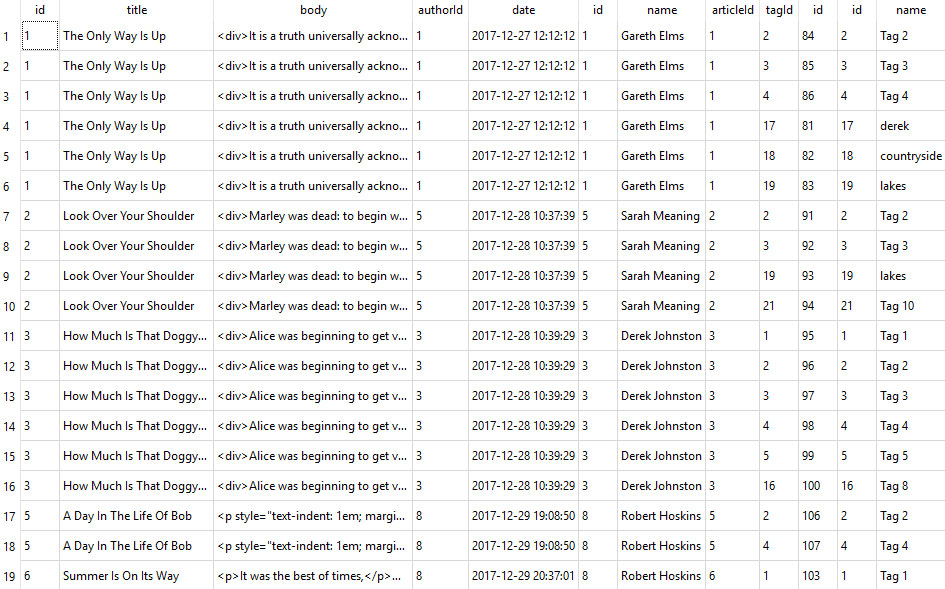
As you can see there is data duplication in the resultset for each tag associated with the article. This is a trade off. The alternative approach is to execute two SQL commands firstly to retrieve the articles/authors (which have a one-to-one relationship) and secondly to retrieve the tags associated with the articles in the resultset ie; two SQL commands rather than one.
Both approaches are pretty simple to do with Dapper but I chose to use the single SQL command. But this could be the wrong approach in this instance because the potentially hefty article content is duplicated for each tag. So if an article has a 5k body and has 10 tags associated with it then the data over the network will be at least 50k. Ouch!
If this was a real app I'd monitor its performance and decide which is the better option. It depends where the concerns are; with network bandwidth or with the number of concurrent database connections.
Also if you're interested in ArticleRepository.cs there is an example using a transaction with SQLite. I use a transaction to ensure that a chain of commands is executed as a unit or not at all.
It's all on GitHub so if you want to see an ASP.NET Core app using Dapper with an SQLite database download the source code from my GitHub page.
Note: I wrote a similar project for PetaPoco a few years ago for which I wrote a blog post.
Many-to-many relationships with PetaPoco
An example of a many-to-many relationship in a database are blog post tags. A blog post can have many tags and a tag can have many blog posts. So how do you do this in PetaPoco? I’ve added tag support to my PetaPoco A Simple Web App project on GitHub so I’ll explain what I did.

To start with you need to create a link table in your database which will stitch the article and tag tables together. So I created the articleTag table to contain lists of paired article ids and tag ids. This is all the info we need to persist this relationship in the database.

So if we have an article with 5 tags you’ll end up with 5 records in articleTag like this :

Creating these records is a one-liner if you have the article and tag ids :
_database.Execute(
"insert into articleTag values(@0, @1)",
article.Id, tagId);
There is a bit more complexity when it comes to reading article pocos and their tags. There are two ways of doing it :
The naughty+1 way
You could do this :
- Load the articles without the tags.
- Loop through each article and retrieve its tags
- Assign the list of tags to each article in the loop.
This is the N+1 problem and it doesn’t scale well. The more articles you’re loading the more database round trips you’ll make and the slower your app will run. Nobody should recommend this approach, but let’s see it anyway :
public Article RetrieveById( int articleId)
{
var article = _database.Query(
"select * from article " +
"join author on author.id = article.author_id " +
"where article.id=@0 " +
"order by article.date desc", articleId)
.Single
<article>();
var tags = _database.Fetch(
"select * from tag " +
"join articleTag on articleTag.tagId = tag.id " +
"and articleTag.articleId=@0", articleId);
if( tags != null) article.Tags = tags;
return article;
}
This example is just for one article. Imagine it if we were pulling back 50 articles. That would be 51 database round trips when all we really need is 1.
The right way
public Article RetrieveById( int articleId)
{
return _database.Fetch(
new ArticleRelator().Map,
"select * from article " +
"join author on author.id = article.author_id " +
"left outer join articleTag on " +
"articleTag.articleId = article.id " +
"left outer join tag on tag.id=articleTag.tagId " +
"where article.id=@0 ", articleId).Single();
}
Here I am pulling back a dataset that includes the article record, the author record and the tag records. You can tell this is a many-to-many relationship by the double joining first on the articleTag then on tag itself. The results that come back to PetaPoco look like this :

As you can see there is a fair bit of duplication here and this is a trade off you will want to think carefully about. The trade off is between the number of database round trips (number of queries) and result set efficiency (network traffic from the sql server to the web server (or service layer server)). It is best to have as few database round trips as possible. But on the other hand it is better to have lean result sets too. I’m sticking with the right way.
If I was writing a real blogging app I would think long and hard about a single joined query like this because the body content, which could be thousands of bytes, would be returned as many times as there are tags against the blog post. I would almost certainly use a stored procedure to return multiple result sets so there is only one database round trip. However typical non-blogging datasets won’t contain such unlimited text data eg; orders and order lines. So there’s no problem.
Document databases suit this type of arrangement. The tags would be embedded in the article document and would still be indexable.
Stitching the pocos together
See that new ArticleRelator().Map line above? PetaPoco can utilise a relator helper function for multi-poco queries so that each poco is correctly assigned in the data hierarchy. Having the function wrapped in a class instance means it can remember the previous poco in the results.
If you’re using multi-poco queries I urge you to read the PetaPoco documentation on the subject and experiment for an hour or two. All the relator class does is take the pocos coming in from each row in the resultset and stitch them together. It allows me to add each tag to the article as well as assign the author to the article.
Turn around sir
And what about from the other angle? Where we have a tag and we want to know the articles using the tag? This is the essence of many-to-many, there are two contexts.
public Tag RetrieveByTag( string tagName)
{
return _database.Fetch(
new TagRelator().Map,
"select * from tag " +
"left outer join articleTag on articleTag.tagId = tag.id " +
"left outer join article on " +
"article.id = articleTag.articleId " +
"where tag.tagName=@0 order by tag.tagName asc", tagName)
.SingleOrDefault();
}
This is an identical process as with retrieving articles but the tables are reversed. One tag has many articles in this context.
More responsibilities
Having many-to-many relationships does add more responsibilities to your app. For example when deleting an author it’s no longer sufficient to just delete the author’s articles followed by the author record. I have to remove the author’s articles’ tags from the articleTag table too otherwise they become data orphans pointing to articles that no longer exist. Add because we’re performing multiple database calls that are all required to succeed (or not at all), we need a transaction. Like this :
public bool Delete( int authorId)
{
using( var scope = _database.GetTransaction())
{
_database.Execute(
"delete from articleTag where articleTag.articleId in " +
"(select id from article where article.author_id=@0)",
authorId);
_database.Execute( "delete from article where author_id=@0", authorId);
_database.Execute( "delete from author where id=@0", authorId);
scope.Complete();
}
return true;
}
Adding many-to-many support to PetaPoco – A Simple Web App was fairly painless and should fill a small hole in the internet. I’ve had a few people ask about it and it seemed the natural next step for the project.
Am I doing many-to-many wrongly? Would you do it differently? Let me know so I can learn from you.
Added MVC Mini Profiler to PetaPoco – A simple web app
I saw a question on Stack Overflow asking how to setup Sam Saffron’s MVC Mini Profiler to work with PetaPoco and realised it would be a good idea to implement the mini profiler into my PetaPoco example app.
The latest release of PetaPoco included a change that made it very easy to integrate the profiler with PetaPoco if you want to. Prior to the latest version you had to hack the PetaPoco.cs file a little bit or implement your own db provider factory. Pleasingly there is now a virtual function called OnConnectionOpened(), which is invoked by PetaPoco when the database connection object is first created. Being a virtual function you can override it in a derived class and return the connection object wrapped in the MVC Mini Profiler’s ProfiledDbConnection class. Like this :
public class DatabaseWithMVCMiniProfiler : PetaPoco.Database
{
public DatabaseWithMVCMiniProfiler(IDbConnection connection) : base(connection) { }
public DatabaseWithMVCMiniProfiler(string connectionStringName) : base(connectionStringName) { }
public DatabaseWithMVCMiniProfiler(string connectionString, string providerName) : base(connectionString, providerName) { }
public DatabaseWithMVCMiniProfiler(string connectionString, DbProviderFactory dbProviderFactory) : base(connectionString, dbProviderFactory) { }
public override IDbConnection OnConnectionOpened(
IDbConnection connection)
{
// wrap the connection with a profiling connection that tracks timings
return MvcMiniProfiler.Data.ProfiledDbConnection.Get( connection as DbConnection, MiniProfiler.Current);
}
}
I didn’t want to lose the existing Glimpse profiling I had in place so I made my class derive from DatabaseWithGlimpseProfiling, which is already in my project’s codebase, so you get both methods of profiling in one app.
public class DatabaseWithMVCMiniProfilerAndGlimpse : DatabaseWithGlimpseProfiling
This is turning into a profile demonstration app with a bit of PetaPoco chucked in :

You can download PetaPoco – A Simple Web App from my GitHub repository.
PetaPoco – A simple web app
I’ve put together a basic web app using PetaPoco to manage a one-to-many relationship between authors and their articles.

The author poco contains just the author’s name, id and a list of articles the author has written :
public class Author
{
public int Id {get; set;}
public string Name {get; set;}
[ResultColumn]
public List<Article> Articles {get; set;}
public Author()
{
Articles = new List<Article>();
}
}
The Author.Articles list is a [ResultColumn] meaning that PetaPoco won’t try and persist it automatically, it’s ignored during inserts and updates. The Article poco has more properties :
public class Article
{
public int? Id {get; set;}
public string Title {get; set;}
public string Body {get; set;}
[DisplayFormat(DataFormatString = "{0:dd/MM/yyyy}", ApplyFormatInEditMode=true)]
public DateTime Date {get; set;}
[ResultColumn]
public Author Author {get; set;}
[Column( "author_id")]
[DisplayName( "Author")]
public int? AuthorId {get; set;}
public Article()
{
Date = DateTime.Now;
}
}
The Date property has a date format attribute so that in the \Article\Edit.cshtml view @Html.EditorFor(model => model.Article.Date) will display the date how I want it. The Author property is another ResultColumn only used when displaying the Article, not when updating it. In the ArticleRepository I use the MulltiPoco functionality in PetaPoco to populate the Author when the Article record is retrieved.
Setup
By default the app uses the tempdb at .\SQLEXPRESS. This is defined in the web.config :
<add name="PetaPocoWebTest" connectionString="Data Source=.\SQLEXPRESS;Initial Catalog=tempdb;Integrated Security=True" providerName="System.Data.SqlClient" />
The tempdb is always present in SQL Server and is recreated when the database is stopped and started. You can change this to suit your environment. The app will auto generate the tables for you if they don’t exist. In theory if you have SQL Express running you don’t need to do anything to get started
A few details
There are two repository classes; AuthorRepository and ArticleRepository. These classes are where the PetaPoco work lives. As well as loading the Author the AuthorRepository class also loads in the list of articles by that author. I use a relationship relator callback class as demonstrated in the recent PetaPoco object relationship mapping blog post. I made a slight tweak to handle objects that have no child objects at all otherwise there was always a new() version of Article in the list. The fix is simple :
if( article.Id != int.MinValue)
{
// Only add this article if the details aren't blank
_currentAuthor.Articles.Add( article);
}
I tried to get this working with an int? Id, but had type conversion problems in PetaPoco. I’ll investigate that later as it would be useful to have int? Id to indicate a blank record
I’ve used the Glimpse PetaPoco plugin by Schotime (Adam Schroder). Because the Glimpse plugin uses HttpContext.Current.Items all the SQL statements are lost when RedirectToAction() is called from a controller. I got around this by copying the PetaPoco Glimpse data into TempData before a redirect, and from TempData back into the Items collection before the controller executes.
This means you still see update/insert/delete SQL. It is definitely a requirement to perform a RedirectToAction() after such database calls so that it isn’t possible to refresh the screen and re-execute the commands (ie; cause havoc). If the user did refresh the screen (or otherwise repeat the last request) they’d just get the redirect to action and not the request that fired the database action.
I expect this to be a common pattern with Glimpse plugins that use response redirects.
UPDATE
Many thanks to Schotime who showed me that the Remote tab in Glimpse shows you the last 5 requests. All the SQL is there in Glimpse if you look for it. I didn’t realise this when I added the TempData solution
:) but at least using TempData the SQL commands prior to a redirect are visible right on the PetaPoco tab without having to drill down to the previous request, which I kinda like as it’s more intuitive and effortless.
Hope this is useful to someone. You can download the source at GitHub. This is my first project using git so if there are any problems please let me know.
Finally, I’ve cut my finger and I’m angry with my cat.
Help getting started with PetaPoco
I’ve recently spent some time working with PetaPoco. As always with something new I found problems early and often but not real problems with PetaPoco itself, just typical “What does this error mean?” and “How do I do this then?”
The kind of objects I want to use with PetaPoco are domain entities so there’s a bit more meat to them than a flat poco. Here are the test classes I started with :
public class Author
{
public int id {get; internal set;}
public string name {get; internal set;}
}
public class Article
{
public int id {get; internal set;}
public string content {get; internal set;}
public string title {get; internal set;}
public Author author {get; internal set;}
}
The property setters are internal so that client (application) code using the entities cannot change their values. The only way these properties would be changed is either :
- in the repository when the entities is being loaded (hydrated)
- during construction or through a builder class
- through public methods on the entities
In my real code I’ll use the InternalsVisibleTo attribute on the classes to ensure that outside of the domain classes only the repository assembly can access the setters. This test is stripped right back so the only remnant of these requirements are the internal setters. Also notice that there is a relationship between Article and Author; when I load an Article I want the Author to be brought back too. So now here are the learning curve issues I had :
Querying data
Let’s load a list of articles from the database and join the author table too :
db.Query(
"SELECT * FROM article left outer join " +
"author on author.id = article.author_id")
This throws an exception :
Unhandled Exception: System.ArgumentNullException: Value cannot be null. Parameter name: meth at System.Reflection.Emit.DynamicILGenerator.Emit(OpCode opcode, MethodInfo meth)
This happens because PetaPoco currently only looks for public setters when mapping to pocos and all my setters are internal. This is easily fixed in PetaPoco.cs by changing all instances of GetSetMethod() to GetSetMethod( true) (update: this change was added to PetaPoco core shortly after this post, so you won’t need to apply it)
Now I want to load a single article. Let’s try using the new multi-poco support :
var article = db.Single(
"SELECT * FROM article left outer join author" +
" on author.id = article.author_id");
This doesn’t compile because the multi-poco feature only applies to the Query() and Fetch() functions at the moment so I can only pass in the type of the result which is Article. The solution is simple :
var article = db.Query(
"SELECT * FROM article left outer join author " +
" on author.id = article.author_id where article.id=@0",
1).SingleOrDefault();
Inserting data
Ok let’s try and insert a new article. We’ll leave out the author for now and see if the foreign key constraint in the database kicks in.
int newRecordId = (int)db.Insert( new Article() {title="Article 1",
content="Hello from article 1"});
PetaPoco didn’t like it :
Unhandled Exception: Npgsql.NpgsqlException: ERROR: 42P01: relation “Article” does not exist at Npgsql.NpgsqlState.d__a.MoveNext()
I’m using PostgreSQL and it seems that it is case sensitive, if I change my class names to all lower case it works. But I don’t want to do that so all I need to do is use the TableName attribute which overrides the convention of class name equals table name :
[TableName( "author")]
public class Author
{
public int id {get; internal set;}
public string name {get; internal set;}
}
[TableName( "article")]
public class Article
{
public int id {get; internal set;}
public string content {get; internal set;}
public string title {get; internal set;}
public Author author {get; internal set;}
}
Now I can get a bit further but I still get an error :
Unhandled Exception: Npgsql.NpgsqlException: ERROR: 42703: column “author” of relation “article” does not exist at Npgsql.NpgsqlState.d__a.MoveNext()
This happens because my poco has an author property and this doesn’t map directly to the author_id column on the database. The author_id column is an integer, so how can I pass my poco into Update() and have it use an author id? You can’t. Instead you need to use a different overload of the Insert() method :
int newRecordId = (int)db.Insert( "article", "id", true,
new {title="A new article",
content="Hello from the new article",
author_id=(int)1});
We are now no longer using the poco, we are using an anonymous type. This is doubly useful because we now have the option to just update specific columns if we want to. Code calling my repository will still pass in a poco but the repository will strip out the values it wants to update. I like that.
In this example I already knew the author id because the user will have selected the author from a drop down while entering the article details.
Updating data
Now let’s update an existing article :
var newArticle = db.Query(
"SELECT * FROM article left outer join author on" +
"author.id = article.author_id where article.id=@0",
1).SingleOrDefault();
newArticle.content += " The end.";
db.Update( newArticle);
Here is this code’s exception :
Unhandled Exception: System.InvalidCastException: Can’t cast PetaPoco_MultiPoco_
Test.Author into any valid DbType.
at Npgsql.NpgsqlParameter.set_Value(Object value)
Again, PetaPoco can’t map the author property to a column on the article table. The way around this is the tell PetaPoco that the author property shouldn’t be used during inserts or updates. We use the ResultColumn attribute for this :
public class Article
{
public int id {get; internal set;}
public string content {get; internal set;}
public string title {get; internal set;}
[ResultColumn]
public Author author {get; internal set;}
}
Now we get another error, remember that I’m using PostgreSQL here :
Unhandled Exception: Npgsql.NpgsqlException: ERROR: 42703: column “ID” does not exist at Npgsql.NpgsqlState.
d__a.MoveNext()
This happens because PetaPoco will use “ID” as the default primary key if you don’t specify it. There are three solutions to this. Firstly I could change my database to use “ID” as the column name. Secondly I could change PetaPoco.cs to use “id” as the default. This would be done in the constructor for the PocoData internal class :
TableInfo.PrimaryKey = a.Length == 0 ? "id" : (a[0] as PrimaryKeyAttribute).Value;
Thirdly, and preferably, I’ll use the PrimaryKey attribute on my poco classes :
[TableName( "author")]
[PrimaryKey("id")]
public class Author
{
public int id {get; internal set;}
public string name {get; internal set;}
}
[TableName( "article")]
[PrimaryKey("id")]
public class Article
{
public int id {get; internal set;}
public string content {get; internal set;}
public string title {get; internal set;}
[ResultColumn]
public Author author {get; internal set;}
}
Also note that if we want to update the author we’d just do a separate call to Update(). If I find anything else worth sharing I’ll update this post
The move towards micro ORMs
Many of us know about the apparently recent appearance of micro ORMs thanks to Rob Conery’s Massive followed by Sam Saffron’s (and Stack Overflow’s) Dapper and more. However, having read around the web it is clear that micro ORMs have existed for as long as ADO.NET, but without the publicity. Some developers don’t like their SQL taken away from them and don’t like the idea of using a heavy ORM if they can help it. So they write their own object mapper that works for them. Of course there are many advantages to using a mature fullsome ORM, it just depends on how you look at it and what’s important in your world
I’ve been resisting using LINQ to SQL / EF / NHibernate partly because I was concerned about efficiency and control but mainly because at work I’ve just not needed to change the data access layers nor have I had the opportunity to do so. I inherited a data access layer that mainly uses stored procedures and ADO.NET and there’s no need to change this. There’s nothing wrong with it and it’s stable and switching to an ORM would be virtually impossible. Does a stored procedure heavy application even suit an ORM? Perhaps for reads
But at home it’s different
At home it’s different. I’m building an application that is still in it’s early stages so I can spend time experimenting with micro ORMs. From what I’ve seen so far I like them all because :
- they are closer to the metal
- the source code is right there for you to step into
- they are much faster than full ORMs
- the learning curve is much shorter
The downside is that you need to know a little SQL to make the most of them, but this excites me! SQL is already a mature ubiquitous DSL for accessing data. If you can talk this language you are at a serious advantage than if you’re relying on an ORM to generate the SQL for you. Dapper and PetaPoco both share a slight optimisation complication in that they both dynamically generate poco mapping methods for your pocos using System.Reflection.Emit.ILGenerator. I tend to skip past that bit in the source for now  but guess what… these two are the fastest C# based micro ORMs available right now
but guess what… these two are the fastest C# based micro ORMs available right now
I’ve experimented a little with Massive, Simple.Data, Dapper and PetaPoco with PetaPoco looking like my personal favourite. I’ve spent most of my experimentation time with PetaPoco so I’ll follow this post up with a list of learning curve problems I had.